近日,复旦大学工程与应用技术研究院(简称工研院)智能感知与无人系统实验室(简称IPASS,https://ipass.fudan.edu.cn/main.htm)撰写的题为《Robust Adaptive Ensemble Adversary Reinforcement Learning》的学术论文被机器人领域顶级期刊IEEE ROBOTICS AND AUTOMATION LETTERS录用,张立华教授、董志岩青年副研究员为通讯作者,博士后翟鹏为第一作者。
Robust Adaptive Ensemble Adversary Reinforcement Learning
论文作者:翟鹏,侯泰先,姬晓鹏,董志岩,张立华*
深度强化学习(DRL)已成为训练连续控制器的常用方法,广泛应用于机器人控制和导航领域,并在模拟器中的性能优于传统的模拟方法。然而,DRL的实际部署却很困难,这是因为模拟器和真实环境之间的差异(如建模误差和干扰)将降低策略的性能。为了解决该问题,本论文结合经验层机器直觉与人类举一反三启式训练学习方法,模拟了人类“老司机”经验直觉的产生机理,一方面,引入镜像架构将对抗架构中的主智能体与对抗智能体解耦,增强对抗训练的稳定性,模拟人类直觉的外部刺激;另一方面,引入PID控制器并将训练过程建模为被控对象,通过控制对手智能体的输出强度来稳定训练过程中的对抗强度,模拟了人类直觉中经验积累的过程。RAEARL算法具有以下优势:1)强鲁棒性;2)高适应性;3)可扩展性。审稿人评价这项工作提出了一种新的具有多个对手的鲁棒对抗RL算法,并在许多实际场景中证明了该方法的有效性,具有相当新颖的贡献。
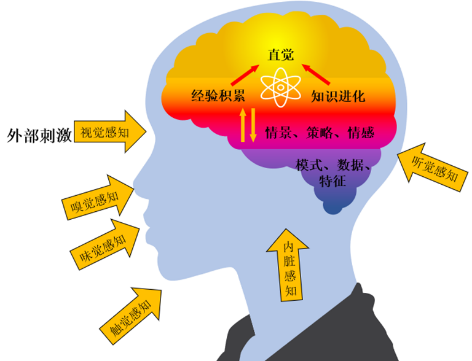
图1. 人类直觉机理
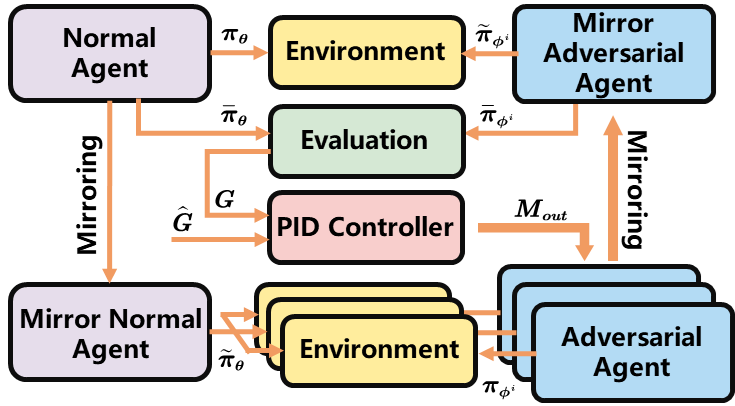 图2. RAEARL算法架构
图2. RAEARL算法架构
RAEARL在强化学习通用实验环境MuJoCo和无人机姿态控制仿真平台GymFc上分别进行了仿真测试,除此之外本论文还将在仿真平台GymFc上训练好的策略直接移植在真实无人机飞控中而无需任何策略优化。广泛的仿真实验证实了RAEARL在提升强化学习策略鲁棒性和训练过程稳定性上的优势。
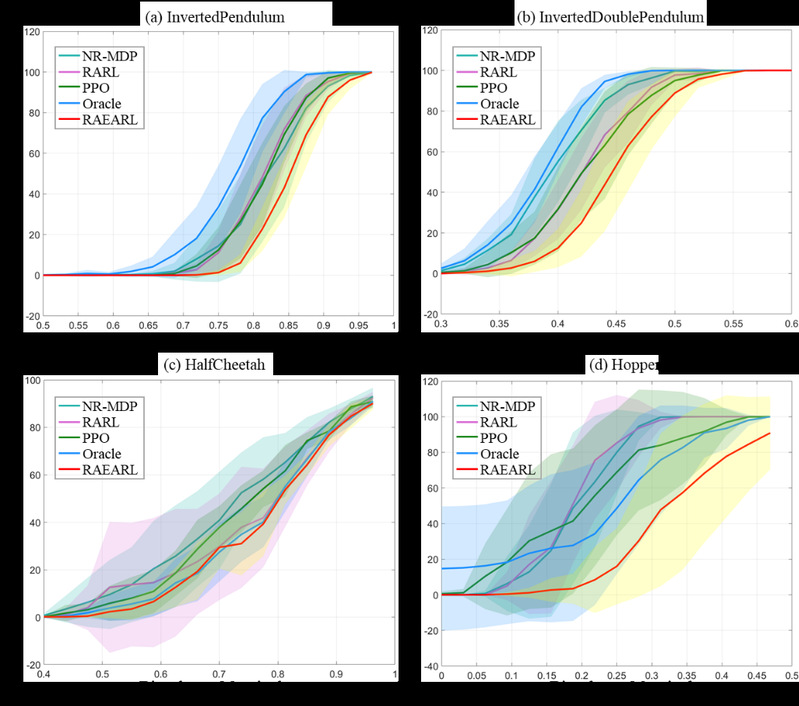
RAEARL与传统方法对比
真实无人机飞控上的实验表明RAEARL生成的神经网络控制器优于基于硬件在环的PID控制器,证明了该方法在sim-to-real方面的潜力。

RAEARL飞行控制器携带不同质量负载的飞行轨迹
IPASS实验室一直秉承着原创理论研究与实际技术落地并重的严谨治学态度,强调要将实验室的研究落地,从解决实际问题出发做研究。本论文从强化学习实际部署困难这一问题出发,结合人类直觉机理与鲁棒控制理论,跨越了强化学习Sim-to-Real的鸿沟,推动了强化学习的落地应用。这篇论文是受人类直觉启发的机器直觉中浅层直觉-经验层直觉的进一步探索,未来将通过博弈论、新材料、数字孪生、认知科学、脑科学与脑启发等多学科交叉创新研究推动机器直觉这一新的交叉学科方向的进一步发展。
延伸阅读:
智能感知与无人系统实验室(IPASS)隶属于复旦大学工程与应用技术研究院智能机器人研究院,近年来一直在机器直觉、人机物融合智能等新一代人工智能理论、脑机解码与脑启发人工智能、智能感知与人机交互、计算机视觉与数字孪生、行为识别和情感分析、智能芯片与智能硬件,以及智能机器人、智能网联汽车、智慧医疗等领域开展交叉创新研究,相关学术成果发表在Nature主刊和中国科学等国内外顶级期刊与国际会议。
Robotics and Automation Letter(RA-L)于2015年6月1日由机器人与自动化协会(RAS)发布。该期刊的范围是发表同行评审文章,及时、简明地介绍创新的研究思路和应用结果,报告机器人和自动化领域的重要理论发现和应用案例研究。
(转自:复旦大学工程与应用技术研究院)

