近年来,随着人工智能应用场景的爆发,人工智能算法的算力需求增长已经显著超越了芯片摩尔定律。传统的计算芯片在计算资源、时延、功耗上越来越无法满足人工智能高并行计算的需要。在智能芯片上,传统的冯诺伊曼架构围绕计算为中心,处理器与存储器本质上是分离的。两者之间的大规模数据搬移,随着摩尔定律的演进,正在迅速限制计算系统的能效和性能。因此,传统芯片架构面临着“存储墙”和“功耗墙”的问题,难以满足人工智能应用的低时延、高能效、高可扩展性的需求。为克服上述瓶颈,存算一体(Computing-In-Memory,CIM)架构通过将数据存储单元和计算单元融合为一体,彻底消除不必要的数据搬移,极大提高了算力和能效。该技术在需要密集访存的AI应用中展现出超高的能效,并被应用于高能效机器学习片上系统(System on Chip,SoC)被认为是下一代人工智能芯片的关键技术。
近日,复旦大学工研院张立华课题组参与的芯片院存算一体智能处理器研究团队,针对后摩尔时代的人工智能处理器设计的相关挑战,提出了多芯粒集成存算一体人工智能芯片COMB-MCM。该系统在发挥存算一体“非冯”架构的性能和能效优势的同时,避免模拟计算电路的计算误差,并且利用多芯粒集成技术实现了流片后的算力可扩展性。
这项工作主要从三个层面进行了技术探索和创新。在架构层面,提出了基于SRAM的存边计算型存算一体架构(Computing-On-Memory-Boundary,COMB),进一步减少现有存算融合系统中权重更新引起的数据搬移,降低系统功耗开销;在电路层面,提出了支持细粒度双极稀疏感知的存算融合宏单元电路结构,在不增加额外检测电路的情况下兼容任意的稀疏模式,降低人工智能算法的计算功耗;在系统层面,提出了基于逐层流水线的多芯粒算法映射方法,并搭建了多芯粒集成(Multi-Chip-Module,MCM)可扩展系统来支持不同复杂度的人工智能任务。 该人工智能芯片方案分别采用65nm和28nm工艺制造,65nm工艺下通过2.5D封装的MCM系统验证了方案的可行性,并在28nm工艺下实现了更好的性能。
相关研究成果作为论文《COMB-MCM: Computing-on-Memory-Boundary NN Processor with Bipolar Bitwise Sparsity Optimization for Scalable Multi-Chiplet-Module Edge Machine Learning》发表在被誉为“集成电路奥林匹克”的国际固态电路会议ISSCC 2022上并作长报告。微电子学院博士研究生朱浩哲、工程与应用技术研究院硕士研究生焦博、张锦山为共同第一作者,芯片与系统前沿技术研究院青年副研究员陈迟晓为该论文通讯作者。
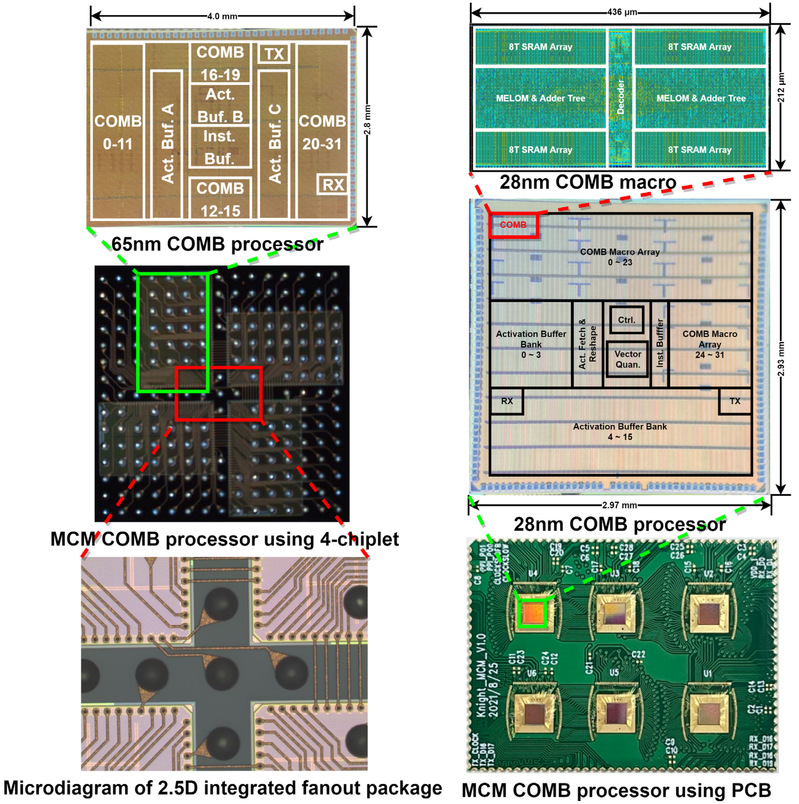
存算融合人工智能芯片“COMB-MCM”及其多芯粒集成封装
(转载自复旦工研院)

